Search Quality at Cliqz
The whys and hows of human search quality assessment
One of the questions that we repeatedly ask ourselves at Cliqz is: “How good is our search quality?”. Not only is it one of our most frequently asked questions, but it is also one of the trickiest to answer. This is because quality is subjective, and at times it has to be quantified. However, this quantification is not straightforward, as all successes and failures cannot be considered equal. You cannot rely on a single number to make a call on quality in absolute sense. What you can do is to use it as your guiding star to see if you are in the right direction or not.
In previous blog posts, we have talked about data collected by Human Web and the technical details of the search, both necessary to build a search engine. Another integral pillar of search engine development is quality assessment. In fact, this is true for more specific use cases of recommendation and e-commerce systems as well. More often than not, machines do a good job at finding relevant results to queries, but we also need to make sure that the results are good from a user perspective. Machines are very efficient at doing what they are programmed to do, however sometimes, they behave unexpectedly. Identifying spam, bad or adult content cannot be done solely at scale by humans, but at the same time, it cannot be left without human supervision either.
In today’s post, we will show:
- The importance of human assessment for search quality evaluation and why it is not easy, even for humans.
- Our manually generated dataset of 700k queries corresponding to 3.5m URLs and how we use them to train our machine learning-based models.
- How we use the assessment data to identify blind spots in the system and fix them.
- Where we stand in comparison to the giants of the field—you can already read some testimonials at the end of the article.
Why We Need Human Evaluation
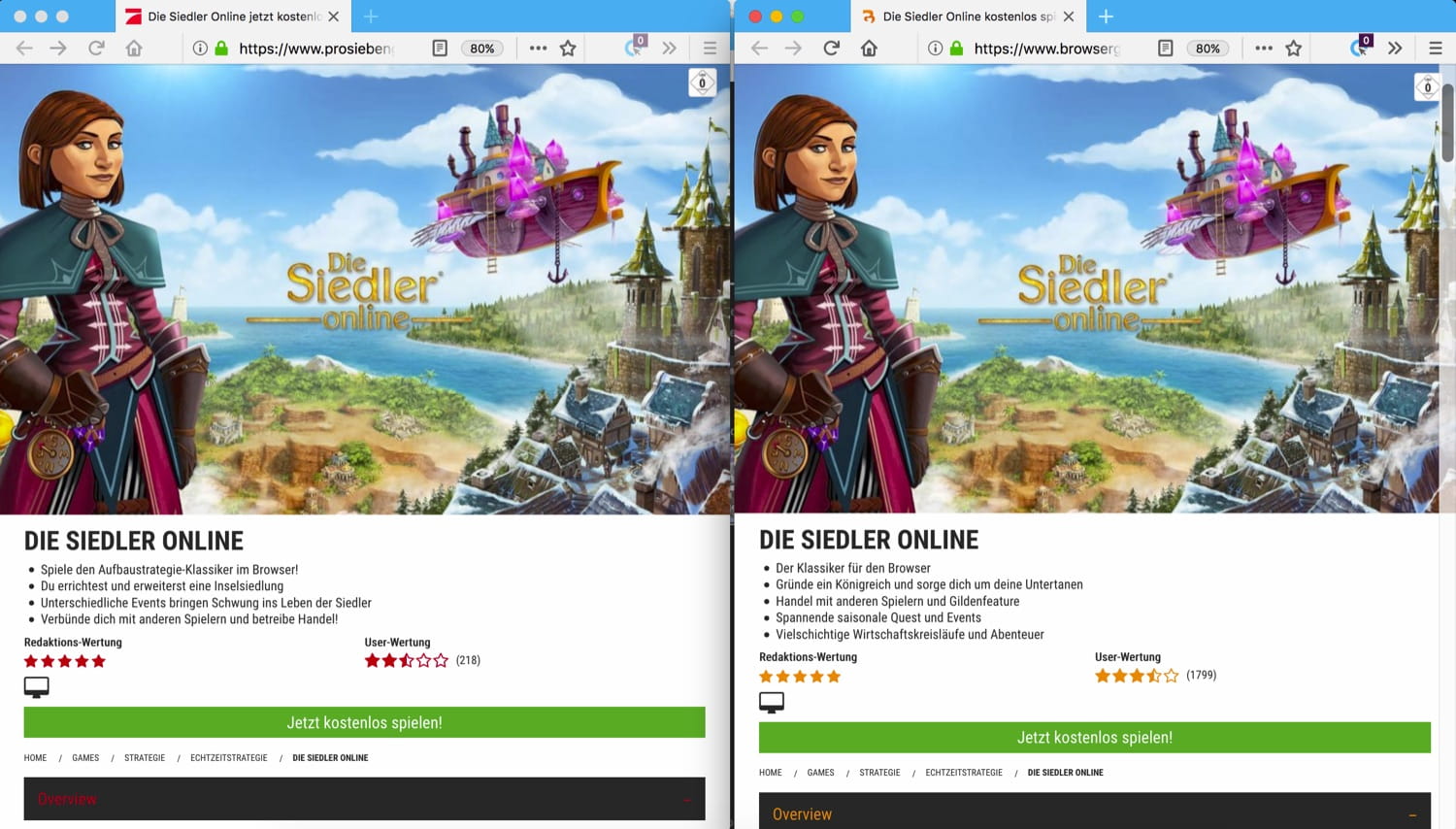
Consider the following two totally different URLs having almost the same content returned for the query die siedler online:
- URL1 – https://www.prosiebengames.de/die-siedler-online
- URL2 – https://www.browsergames.de/die-siedler-online
Looking at the URLs, it is quite impossible to identify that these two pages are duplicates. On the other hand, a quick glance at the pages is enough to know that they are indeed very similar. More recently, we have been able to catch such problems and automatically de-duplicate our results on the basis of page content though.
Consider another example of a snippet in Polish with a grammatical problem, which a native speaker can catch instantly, but is more work for a machine to identify, if at all. If you are curious, the problem here is that “ul.” (see Figure below) is an abbreviation of the term “street” which (1) requires a street name after it and (2) does not signify the end of the sentence, hence the snippet should end at an ellipsis to show continuity.

Identifying user intent from partial search queries and responding accordingly is an essential feature of a search engine. For example, when the user is looking for weather mun, it is more probable that the user intent is to check Munich’s weather in Germany, and not that of a tiny district Tuen Mun located in China (also, it is highly unlikely that even Chinese would refer to Tuen Mun as simply Mun—PS: we checked).

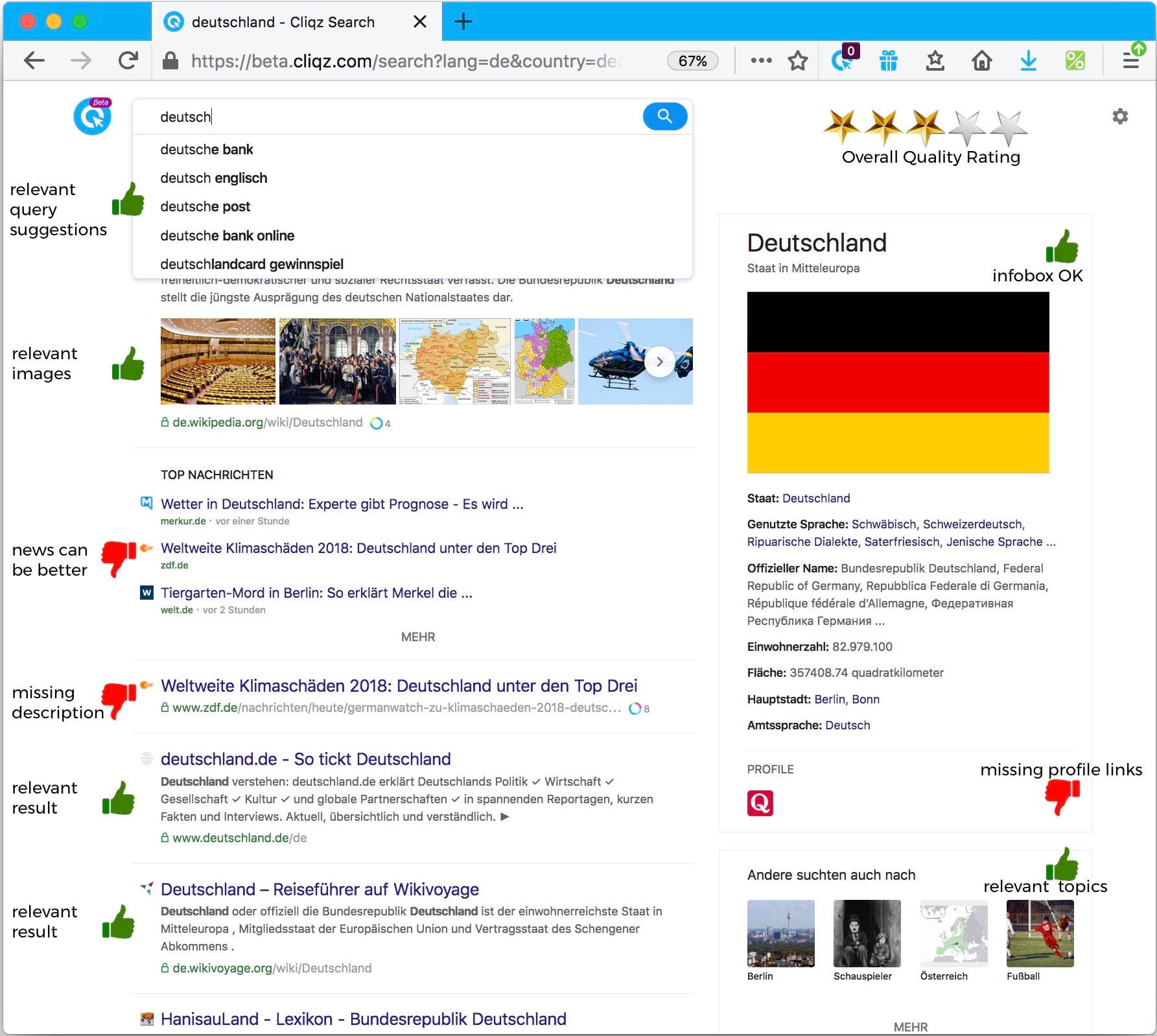
To answer the question “What is a good quality result?”, it is important to first define what is perceived as NOT a good quality result. In other words, will the users be happy when they see the given set of results? Some further scenarii requiring a human eye for quality check include, but are not limited to: identifying missing (vital) pages and 404s, catching adult or duplicate content, foreign language pages, missing text or bad formatting, design issues, location sensitivity, etc.
Moreover, we need to know the overall look and feel of the SERP, which is a combination of query suggestions, individual results, implicit comparison with other players, breaking news and past experience; it cannot be codified or indicated by a mere collection of metrics.
How does the Human Evaluation Work?
Keeping in mind the need for having large amounts of statistical data on one side—to have conclusive numbers measuring search quality—but also having a human eye to catch the quality issues mentioned above, we came up with a tiered solution for quality measurement. With a team of quality analysts and search quality raters, we do weekly assessments of sets of search results under a strict set of guidelines. These guidelines have evolved over time to adapt to the needs of the system, and essentially help us in evaluating the relevance of URLs returned as a response to the user queries.
Over the course of years, we have manually evaluated approximately 700k distinct queries from all over the world including, but not limited to, Germany, the USA, Canada, the UK, Spain, Russia, France, Italy and Australia accounting for over 3.5 million URLs. In addition to quality monitoring, this data is also used to train the system, as explained in our blog post on Building a search engine from scratch. Without going into much detail, we now explain how the human evaluation process works:

Pre-Processing: Data Preparation
Preparing data for an assessment can roughly be divided into two parts: (1) select queries for the assessment and (2) get corresponding URLs from the system. This data is then uploaded to an in-house built assessment tool, which is used for evaluation. When generating data and assessing them, we need to ensure that we:
- Cover a full range of query frequencies—we extract queries from our Human Web data (our anonymous data collection system; which we discussed in our previous post). It is important that we cover high-, mid- and low-frequency queries, because otherwise results will be biased—as intuitively the system performs better on high frequency queries than on low-frequency queries. Thus, we use a bucketed approach and pick up queries from 10 different buckets equally, corresponding to a range of frequencies.
- Cover full and partial queries – the set of results and system performance to a partial query (e.g.
ru) can be very different from a full query (e.g.ruby). - Assess news-related queries—news has a different set of requirements compared to general search due to its fast-moving, ephemeral nature, so it is important to monitor news system for correct triggering and updated results.
- Cover hard queries—these are the long-tailed queries that need to be evaluated for monitoring and improving the system.
- Evaluate and re-evaluate queries—since the system is continuously improving, it is important that we re-evaluate the queries with new results. Hence, every week, 70% of the queries evaluated are new, and 30% are repeated.
- Set the right index (based on country), language and filters: i.e. the correct locale, and if the adult filter should be turned on or off.
- Assess fresh and real-time search—these systems update themselves every few minutes, and the classical weekly assessment model doesn’t work in this case.
Human Evaluation
The actual evaluation requires us to understand the query before we assess the URLs and assign a rating category. One major problem is that all raters (being humans) are different. We try to homogenize the ratings, but what for someone might be “slightly-relevant” for another might be “relevant”. Hence, we have special procedures in place to evaluate the quality of evaluators, and ensure that everyone is consistent in their understanding of the guidelines and almost equally strict (or lenient) in assigning the categories. Being a rater is not an easy task, believe us.
We briefly describe each of these three components below:
Understanding the Query
To be able to have a correct assessment, we first have to understand the query before we can assign the ratings to the results. Assessment of a query is not easy, even for a human. E.g., what does "Saturn" mean? And "Munich Madrid " (notice the space after Madrid)? And "gm"? A query without a context can often be misleading, even more so when you try to interpret it as it is being typed. The context is only in the head of the person typing the query. Not even Google reaches so far, at least not yet :-)
We have to work with the raters so as to not jump quickly into an assessment, but try to figure out multiple contexts for the same query. This is because the results can vary on the basis of:
- User intent, e.g.
Appleas a company vs. as a fruit. - Partial or full query, e.g.
Martin Lutherhas different intents if considered as fully or partially typed. - User locale, e.g. German results would be fine for people in Germany, but may not be the desired results elsewhere.
- Type of query, e.g. navigational (
www.facebook,Lady Gaga,amazon), informational (opening hours rewe,weather orlando), and transactional (buy iphone X,download Cliqz).
The most common scenario is that a single query has several interpretations, because queries are usually not so explicit: facebook may refer to visit the Facebook page, learn about Facebook on Wikipedia or get information on Facebook stock options. This is where the interpretations come into play:
- Major interpretation—what most users mean when typing the query. In other words, the most likely meaning of a query term. This major interpretation should be clear. Not every query has a major interpretation, and it is possible that a query has more than one.
- Probable interpretation—what some users mean when typing a query, or a likely meaning of the query. Every query may have multiple common interpretations.
- Minor interpretations—what only a few users have in mind. An unlikely interpretation of the query. Again, every query may have multiple common interpretations.
Assessing the URLs
To evaluate the URL, we ask the following questions (and many more):
- Authority—is the page source or content trustworthy? Is the content appropriate for the query? Is this a page managed by a government body? Is it the official social media account of a celebrity? Is it the official homepage of a business? Would you mind giving your credit card information? Would you download (say) a software from here?
Sometimes user-generated content (e.g. forums) are authoritative and useful, because of the guidelines and quality control by the site owners, e.g. Wikipedia, Stack Overflow, Hacker News.
- Scope—does the content of the result match the query in range and depth?
- Quality and User Experience—does the page provide a good user experience?
There are certain signals that let us evaluate the page, like SSL Certificate and HTTPS protocol, number of views (e.g. YouTube), upvotes to certain answer (e.g. Stack Overflow), references cited (e.g. Wikipedia), etc.
The Ratings
Based on the context and intent of the query and evaluation of the page, the URL is given a rating as per the following rating categories:
1. Vital
- Official result of an entity (i.e. person, place, company, product or organization).
- Query needs to have only one dominant or major interpretation.
- If a query does not have a major interpretation, there is no vital result.
- If you are not sure because in your opinion two results may be rated as vital, rate them as useful (explained next).
Queries with vital results: HTC 11, Angela Merkel, apotheken umschau, vice, bundesliga, o2
Queries without vital results: smartphones, us presidents, apotheke, news, tore leverkusen darmstadt, mobile tarife
2. Useful
- Helpful, important result to many/all users.
- Perfect match to the query.
- The result fits the major interpretation in a satisfactory way.
- Well-known and/or specialized webpage.
- The content is:
- High-quality and well-organized.
- Very convincing, reliable, entertaining, and/or up-to-date.
A useful result could be found on SERP’s top 3 search results and it is so helpful that the user doesn’t need to look for other results.
| Query | Corresponding Useful Result |
|---|---|
| USA | https://en.wikipedia.org/wiki/United_States |
| neuer | https://en.wikipedia.org/wiki/Manuel_Neuer |
3. Relevant
- Helpful to several users.
- The result is correlated with the query, but if compared to a useful result, it may be:
- Less detailed.
- Not fully up to date.
- Not a really convincing source.
- Covering a partial aspect of the query only.
- Covering a common, but not the major interpretation.
- Some users would be happy with this result but may want to look for further results. In short, this is a good result, but not as good as a useful one.
When a query has no major interpretation, which usually happens with incomplete queries, we rate the results as relevant, if they meet the possible intents satisfactorily.
| Query | Corresponding Relevant Result | Comments |
|---|---|---|
| www.sea | https://sealoffantasy.de | This result only covers one of the probable intents |
| h and | https://www2.hm.com/en_us/men.html | This result covers only a limited scope |
4. Slightly Relevant
- Not helpful for most users.
- The result is somehow related to the query, but if compared to a useful or relevant one, it may be:
- either too specific or too general for the query (scope fail).
- of inferior quality or providing less information.
- Covering a less likely or minor interpretation.
- Completely outdated.
- We use this category to rate international e-commerce sites displaying products that are already available from the user’s country.
- In short, this is a bad result, but still related to the query.
- A slightly relevant result can be considered as a “starting point”. That is, a website in which the user has to start looking again because it is so specific that it requires another search and a couple of clicks until reaching a potentially relevant or useful site.
| Query | Corresponding Slightly Relevant Result | Comments |
|---|---|---|
| Munich | https://www.imdb.com/title/tt0408306/fullcredits/ | This result covers a minor interpretation - also in a limited scope: the main interpretation is the city of Munich. |
| map seoul | https://www.lonelyplanet.com/maps/asia/south-korea/seoul/ | The quality of the page is really poor: neither information about public transport, nor accommodation, nor restaurants. The map is not interactive, and it is not possible to zoom. |
5. Off-topic / useless
- It is not helpful for any user.
- The result is not good and it should not be shown at all, because of one or more of the following reasons:
- It does not meet the user intent. Even if the result might be related to the query, the detail the user is specifically looking for is missing.
- It deals with a different matter.
- It just shows meta-information regarding a popular domain.
- The purpose of the website is to cheat the user (e.g. providing a SERP with unrelated items).
- It is a spam page.
| Query | Corresponding Useless/Off-topic Result | Comments |
|---|---|---|
| breaking bad online streaming | https://de.wikipedia.org/wiki/Breaking_Bad | The result does not meet the user’s intent, i.e. watching the series “Breaking Bad” online. It is a good, authoritative, well-structured and comprehensive page, but does not provide what the user wants. |
| amazon.com | https://www.whois.com/whois/amazon.com | The major intent is either to land on Amazon’s homepage or to find information related to the company. This page just shows metadata about the domain: IP address, location, status, etc. |
In addition, if the page is not available anymore (e.g. hard or soft 404s and private pages, it is rated as Not Found. Pages in a Foreign Language are rated accordingly as foreign. Finally, adult and spammy pages are independently marked with special flags. Each page gets one rating and one or more flags.
Post Processing
The assessed data is received in the form of the tuple:
{
query: [
<url1, assessment1>,
<url2, assessment2>,
…
<urln, assessmentn>
]
}
which undergoes further processing for analysis and stats generation in the following dimensions:
- Stats generation
- Training the system
- Pattern analysis for trend extraction
- Feeding blacklists
Let us have a look at each of them in a little bit more detail.
Stats Generation
In its simplest form, the stats are an accumulation of all the assessments to-date, categorized with respect to ratings. This helps as a weekly monitor in case the system goes down and/or if the good categories drop or bad categories go up. These stats are also helpful to compare multiple systems and as pre-release sanity checks.
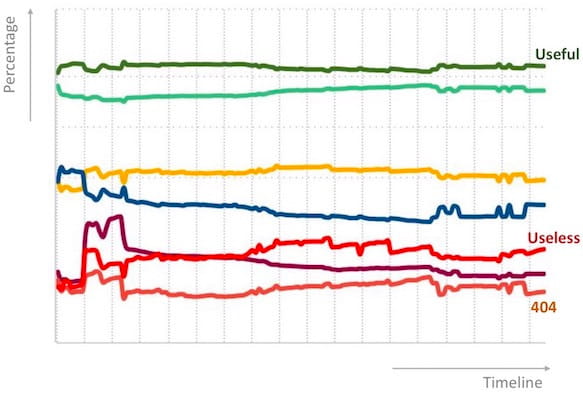
Another useful metric is frequency- and position- based insights w.r.t. ratings. Not all queries are created equally; also not all results have equal weight – a bad result for a highly frequent query e.g. weather Munich is worse than a bad result for a rarely typed query e.g. the isley brothers motown anthology discogs. Similarly, a bad result at first position is more critical to fix than one at fifth position. It is sometimes important to have a one-to-one comparison of multiple systems. In that case, we calculate a per-query score as follows:
Where, is the number of URLs for a query.
The scores are then accumulated across the complete set for direct comparison. This strategy is typically used while developing a feature and for fine-tuned observations and examples over multiple iterations. It is important to note that the numerical value is extremely dependent on the methodology, which makes it difficult to interpret in isolation. It is very easy to end up with a comparison between “apples and oranges”. That is one of the reasons why we are not stressing any number in particular in here, as we would not be able to describe in detail the methodology, criteria of reviewers, distribution of queries to be assessed, etc.
Training the System
As explained in our post on building a search engine, this data serves as a ground truth for training our ranking system, especially for the long-tailed hard and un-seen queries. The search ranking uses hundreds of heuristic and machine learned features. These features were put together with heuristics in our earlier versions of ranking, but now we use GBDTs (Gradient boosted decision trees)[1], which we train using supervised learning. The rating is converted to a numerical score (vital - 10, useful - 6, relevant - 4 and so on…) and we train a regression model on it. This is the first stage of the ranking: to remove irrelevant pages. We later use other models to incorporate popularity. Since the ratings are directly used for training the system, this requires us to be specially careful about our rating quality as inconsistencies can lead to corrupted data and, thus, poor training of the system.
Pattern Analysis for Trend Extraction
The human assessed data is analyzed for patterns and trends in results with low ratings like useless (ratings 1 and 2), and pages not found etc. The problem could be due to a difficult type of query e.g. those with names, numbers, addresses or exceeding a certain length. Or, it could be in the underlying processing e.g. extracting synonyms and forming expansions. We then look at the viability of the solution and focus our efforts on the targeted area.
Feeding Blacklists
This data is also used to feed our adult filter and populate our blacklist of URLs and domains including 404s and spam. These blacklists work in real-time and are also used to filter out bad results quickly. It is important to note that only those results are blocked which are spam (http://www.de.youtube.de.com/), 404 (http://all.tango.me/), adult (only in case the user has turned the adult filter ON) and illegal (example truncated deliberately). We do not censor or de-rank a page on personal choice or point of view.
Our users help us in improving the system by sending us reports of broken pages via our webpage: https://cliqz.com/en/report-url. This page is also directly available in the Cliqz browser control center.
A Race Against Time
Following is a real conversation between a Quality Analyst (QA) and an Engineer (Engr.):
- QA – Hi, I found this bad example (example here) – can you please have a look?
- Engr. – Sure… (a few minutes later) I cannot reproduce it. When did this happen?
- QA – 22 minutes ago…
- Engr. – Ah, too late – the system updated meanwhile, and the bad result is gone now. Yay!
- QA – Oh! Yay!
We are at an exciting phase at Cliqz, where the data updates in near real-time, and classical search quality evaluation doesn’t work. We handle such situations by being extra rigorous in our evaluations during development phase and rely on automated stats to closely monitor the differences with the production system. This allows us to minimize the set of queries that need to be checked manually and overall speeds up the process. At the same time we use our historical data to ensure that nothing critical breaks e.g. vital pages (explained above) remain on top position.
Let’s try Google—a Benchmark
We have automated tests to measure our quality, which are also used to train our models: Basically, against the Google SERP. We know what Google answered for many queries, so we can train the models to try to match them as close as possible, but that only gives us one side of the problem, how similar you are to a state-of-the-art search engine, but it tells us nothing for those URLs that we included in the results which are not part of the results from Google. You might think even without checking that they are wrong, and most probably, you would be mistaken. Many times these URLs, once human assessed, turn out to be very good, sometime not. But thanks to the human assessment we can close the circle.
Quoting from our earlier blog on Cliqz Journey:
Philosophically, we believe copying is a loaded term, we prefer to use the term learning.
We are not copying Google results; we are learning from them! The following examples show that our results, albeit being different, do meet the user requirements and make them happy - sometimes more than others.
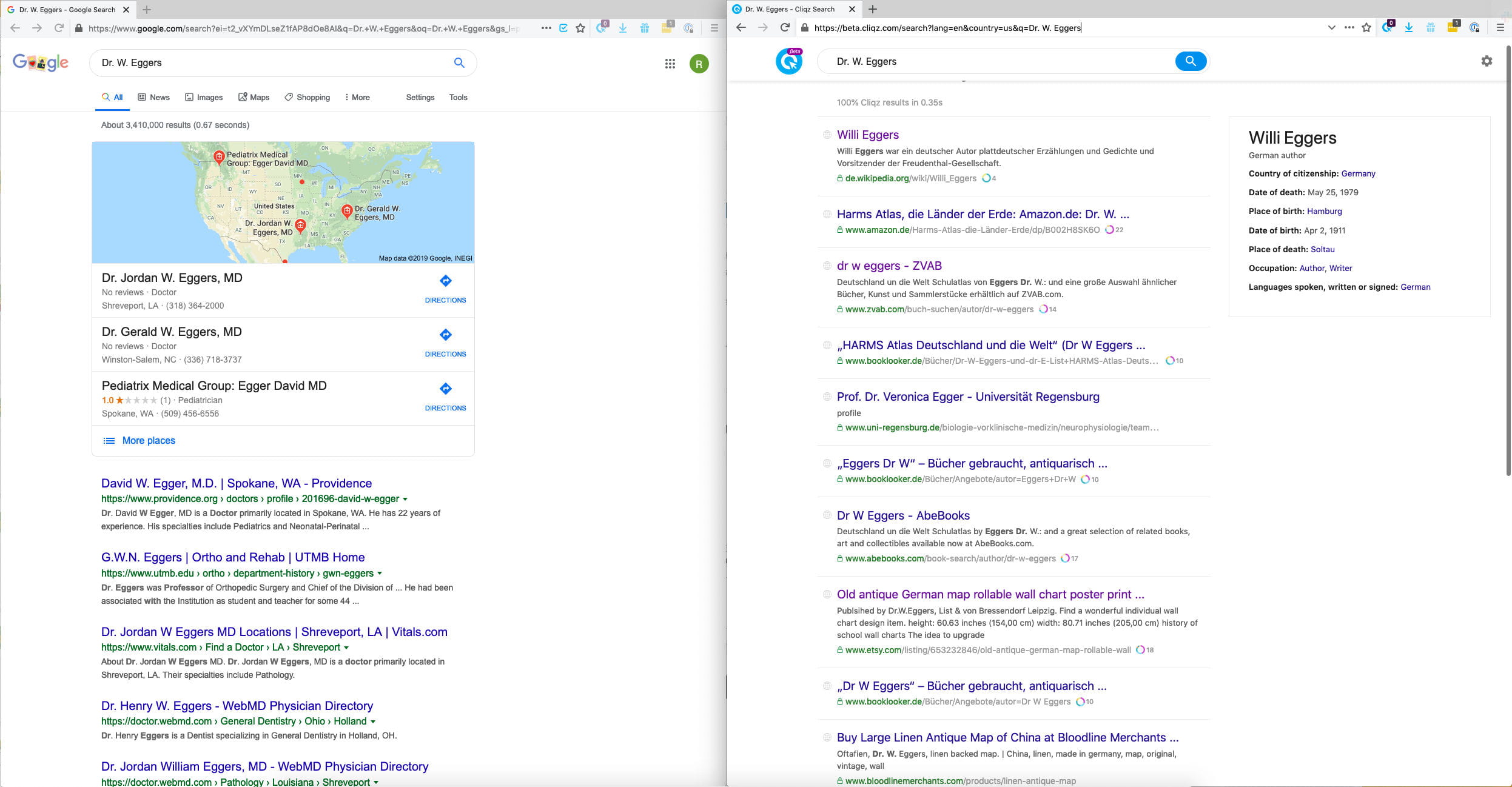
Example 1: This was actually reported by a user[2], who was looking for Dr. W. Eggers - the cartographer. Although Google results below are not bad, the user was happier with our results, because they matched his expectations better.
Example 2: Another example of query titan, where we show significantly different, but good quality results compared to Google.

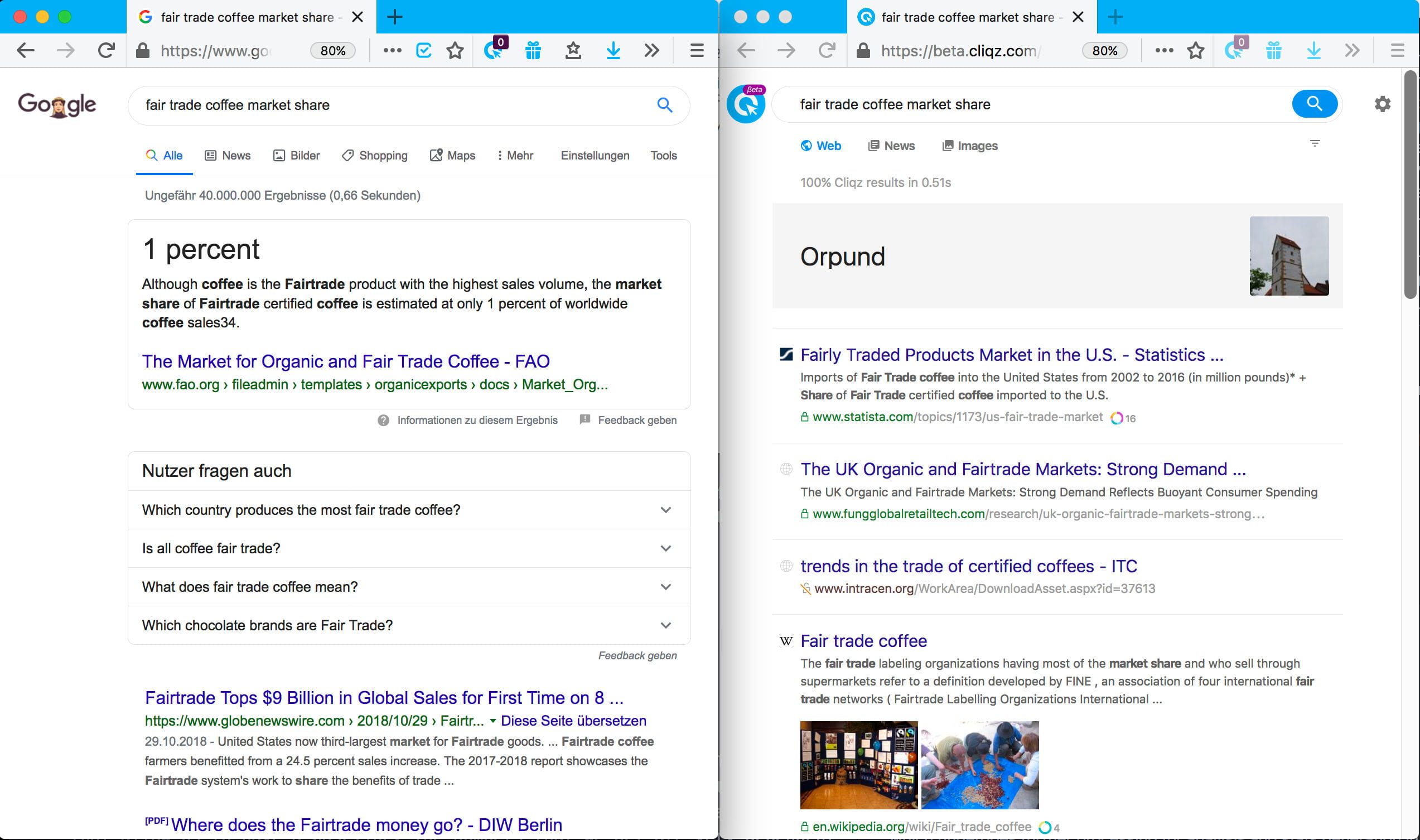
Example 3: Sometimes we mess up too, e.g. for the query fair trade coffee market share, Google gives a correct instant answer, while our results can be better.
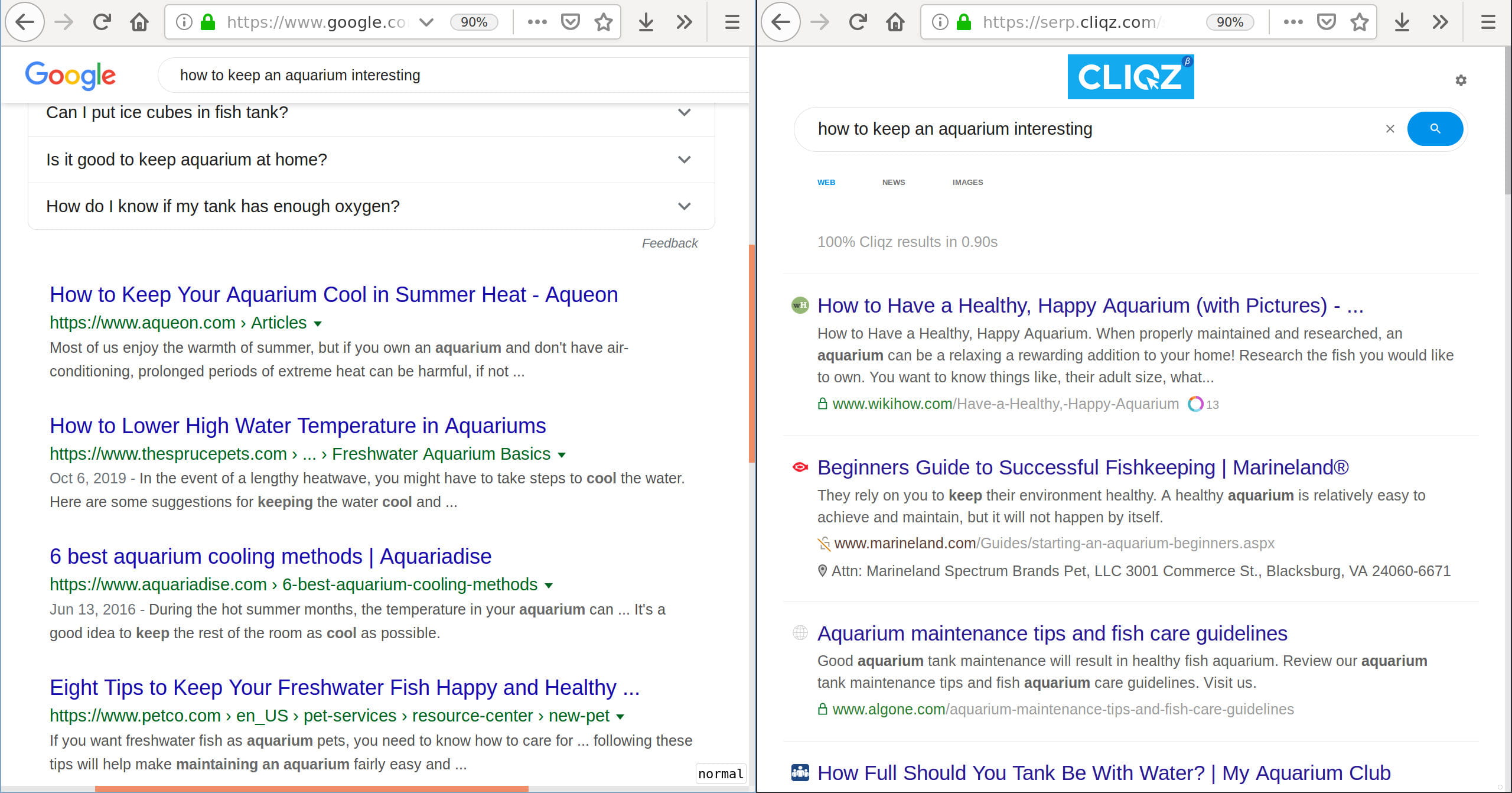
Example 4: However, sometimes Google messes up too, e.g. for the query how to keep an aquarium interesting, Google replaced the term interesting with cool, which resulted in irrelevant results. Our results are quite impressive and relevant in this case.
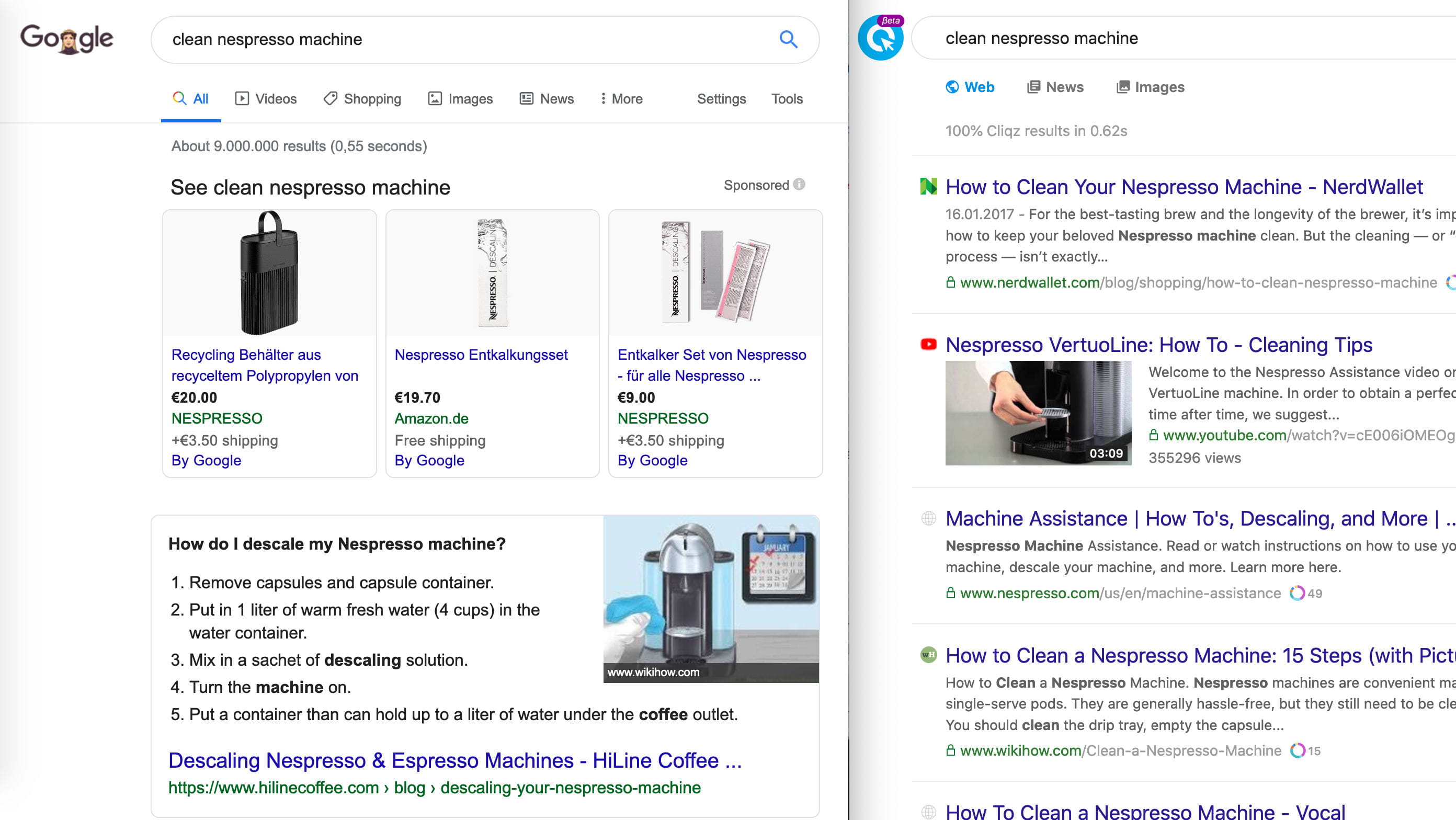
Example 5: And sometimes they have other parameters to optimize for. For example, for the query clean nespresso machine, the user intent is clearly to get information on cleaning their Nespresso machine and not to buy a new one. Our results are clean and relevant in this case.
We also measure quality against the reference search engine at bulk and then do the fine print on a smaller set of query/URL pairs. For sanity, we also human rate query/URL pairs that are returned by the reference search engine, that allow us to have a baseline. The numbers that we get are very dependent on the distribution of queries, strictness of the raters, etc. We have little to no interest in knowing if we are better than Google or not, we only do the measuring with Google for sanity check, what we are interested in knowing is that our quality is steadily increasing.
In the next few days, we will get back with more details on our underlying search technology and infrastructure. We are far from perfect, but reference search engines are not as good as you might think. Or if you prefer, they are awesome, and we are almost as awesome as they are.
References
User—who does not work at Cliqz. ↩︎