A New Search Engine
Cliqz Journey
“It’s a sign of a monopoly that wants to be broken. Everyone’s frustration about this is the water behind a dam. When the first cracks appear, that pressure will burst the dam open. The good news is, that pressure could be used to accelerate a new startup.” — Paul Graham
This blog will see quite a few technical posts over the next week on how the Cliqz search engine works, but we would like to begin with a brief history of our search efforts.
The story begins at the end of 2013. We wanted to take on the audacious task of building a web search engine, that would one day be as good as the big ones. There were only two explicit constraints that we knew we’d be working under:
- Money and Resources : We have been lucky enough to have fantastic investors, who fund and help us in our journey. However, no matter how much money we would receive, it cannot match the resources of our competitors.
- Independence: The search engine would have to be autonomous. Meaning that we would need to build our own independent index and could not rely on a search partnership with any of the heavyweights of the industry. So, the path of Qwant, DuckDuckGo, Startpage, Ecosia and alike, was not an option.
Why the second constraint? one might ask. Besides the obvious potential for profitability, our mission was to fight the oligopoly of Silicon Valley by building a credible alternative. One cannot stake a claim as a true alternative to a service by being reliant on the very same service in order to function. We could get some users, even make some decent money, but our survival would still be at the mercy of the very organizations we were fighting against. Not a great scenario to say the least.
While we might deserve to be called idealistic and naive because of this, we do not believe we are. As a matter of fact, we are extremely pragmatic and willing to cut a lot of corners. Some of which, controversial.
Given the constraints, can we build a search engine?
Although we started with an experienced team, none of us had a traditional search background or knew the best approach to tackle the problem. We did have friends at Google and Bing, so we asked them: How would you start? More often than not, we were met with a laugh, followed by an incredulous stare the moment they would realize we were serious. The experts, who chose to answer, suggested that we should first start with crawling the whole web. We were told that this would take between 1 and 2 years to complete, and would cost a minimum of $1 billion (Again, this was 2013!). Needless to say, this was not a very enticing proposition.
The single biggest challenge: Noise
We did not know much about search, but we knew something very important: noise is the most difficult thing to get rid of. The Web is so vast that any query can be answered. Almost any given term can be found in thousands of documents, but most of them will be irrelevant as an answer. It is like finding a needle in a haystack. The amount of noise introduced in the process makes all the difference between a useless search engine and a great one.
At the risk of gross oversimplification, we can say that a web search engine computes a content match of each document with respect to a user’s question (query), combining the current popularity of the document and the content match scores with some heuristic.
 The content match score measures how well a given document matches a given query. This could be as simple as an exact keyword match, where the score is proportional to the number of query words present in the document.
The content match score measures how well a given document matches a given query. This could be as simple as an exact keyword match, where the score is proportional to the number of query words present in the document.
| query | eggplant dishes |
| document | Here is a list of great dishes one could make with an eggplant… |
Or a more exotic semantic match, where the matching document has no overlapping words with the query.
| query | eggplant dishes |
| document | Here is a list of great recipes one could make with an aubergine … |
With a function that would give us a perfect content match, we would be very close to building the perfect search engine. But the web search problem is a lot harder than what the examples above illustrate. The Web is full of noise and all models are subject to adversarial attacks. Being on the leaderboard of SQuAD2.0[1] is not enough, which is unfortunate.
When attempting to retrieve the two good documents shown above, one would also end up retrieving a lot of noisy documents, such as
| query | eggplant dishes |
| document | Popular Youtuber eggplant dishes out a severe attack against the whole music industry… |
| document | I am not a fan of eggplant, but here are some zucchini dishes … |
| document | Did you know that eggplant dishes cannot be refrigerated? … |
These documents have an exact keyword match with the query, but are probably not what the user is looking for. The problem gets even harder once we use partial and semantic matching. The good documents get buried in a massive pile of mostly irrelevant ones (if solving these problems sounds exciting to you, get in touch with us!).
Reducing noise by using Anchor text
Prior to Google, search providers like Altavista indexed the content of the web page as a primary means to perform content match. This is very noisy, as illustrated in the previous section. When Google came along, they had one big trick up their sleeve (not PageRank, as one might assume). They were the first to use the anchor text on the links to the page to build a model of the page outside of its content. This meant that they had to crawl and store most of the Web to take the back links, not a small task today and extremely challenging back then. By building an index on top of this, they were able to achieve a dramatic reduction in noise compared to their competition at the time. Google’s ranking has, of course, evolved quite significantly since its inception but this reliance on anchor text matching as one of the major ranking signals was a clear differentiating factor early on. As stated by the founders themselves in their seminal 1998 paper[2]:
anchors often provide more accurate descriptions of web pages than the pages themselves.
Anchor text, curated by humans, serves as a mini summary of the content of a page. By building an inverted index based on it rather than the entire content, one can achieve a significantly smaller and more importantly, less noisy index. The ability to infer better summaries of the content of a page leads to building better indices and eventually, a better search.
Building better page summaries with query logs
Query/url pairs, typically referred to as query logs, are often used by search engines to optimize their ranking and for SEO to optimize incoming traffic. Here is a sample from the AOL query logs dataset[3].
| Query | Clicked Url |
|---|---|
| http://www.google.com | |
| wnmu | http://www.wnmu.edu |
| wnmu webct | https://western.checs.net:4443/wadmin/webct_logon.htm |
| ww.vibe.com | http://www.vibe985.com |
| www.accuweather.com | http://www.accuweather.com |
| weather | http://asp.usatoday.com |
| harry and david | http://www.harryanddavid.com |
| college savings plan | http://www.collegesavings.org |
| pennsylvania college savings plan | http://www.patreasury.org |
| pennsylvania college savings plan | http://swz.salary.com |
| amc painter’s crossing | http://www.mrmovietimes.com |
Queries performed by people, if associated to a web page, serve as even cleaner summaries than anchor text. This is because all the logic put in place by the search engine, who resolved the query with a list of web pages, and all human understanding and experience that led one to select the best page from the offered result list end up embedded in the association <query, url>.
These datasets exist in the wild, it is possible to buy them from various providers. So we got our hands on a couple datasets and got to work.
Our Attempts so far
Sure enough, our initial release (April 2014) was a toy search engine. It was merely capable of answering queries that were an exact match to the queries we had in our query logs. Yes, that meant we didn’t have a “real” search-engine, but a glorified cache. We would only be able to answer 50% of the queries while the rest was answered with a nice “we do not have results”. However, it was immediately obvious that it worked better than anything we had tried prior to that. It was a clear validation of our idea. A way to proceed.
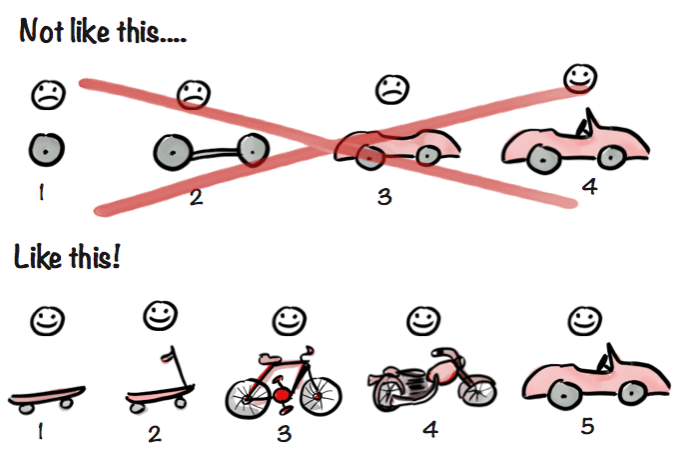
Regardless of how promising initial results looked, they were clearly not good enough to be released as a standalone search engine. The quality was sub par compared to the competition and we did not have enough results. We set out to build a car, instead we built a skateboard. However, this simple skateboard got us rolling. We decided to release our search as a browser extension, and take over the URL bar with search results in the dropdown.
While it started as a compromise between our wish to have a full-scale search engine as soon as possible and already mentioned deficiencies at the time, the dropdown has since evolved to provide a fantastic, unique search experience:
- By putting search results in the URL bar it blends user history and search results in a seamless manner.
- By auto completing keystrokes to actual results and skipping the search result page altogether, it helps users navigate the web ridiculously fast.
- It does not require users to compromise on their search experience, they could still reach their favorite search engine by pressing Enter.
We encourage you to try using the dropdown search on Cliqz browser. It saves time and in cases when it doesn’t have what you are looking for, your search page of choice is only one key stroke away.
Thanks to the Cliqz Firefox extension, we got users. Their searches helped us obtain more query logs through Human Web (end of 2014), an in-house system which collects strictly anonymous data. This ability to collect more query logs with Human Web was the single biggest factor for the improvement in our search quality since then.
Does this mean that we don’t need more data? No, the more data the better because it is what feeds our algorithms and models. They have been iterated many times and are constantly a work in progress. A few notable improvements are:
- Extending exact matches with approximate and synonym matches.
- Query auto-completion and contextual spell correction.
- Semantic matches with word and query embeddings.
- Move from completely heuristic driven to mainly machine learned recall and ranking pipeline.
- Improvements in the search index life-cycle management (from up to 6 months to near real-time updates now).
Most of the time these changes would bring incremental improvements in query coverage. From being able to find results to only exact query matches in the beginning, the search evolved to answer more and more complex and nuanced queries. An upcoming series of posts will delve deep into each of these topics, do check them out!
Today, thanks to these improvements, we can offer a beta version of our own search page publicly. It comes with most of the bells and whistles one would expect from a search engine, while being completely independent.
Give it a try at beta.cliqz.com. We look forward to your feedback as we work hard to improve it every single day.
FAQ
We are sure you have a lot of questions that you want answered. Feel free to reach out to us on any social platform and we’ll try our best to respond. We can start by answering a couple of expected questions beforehand.
Those query logs you collect come (mostly) from other search engines, right?
Yes, the bulk of query to URL associations come out of our users default search engine, which happens to be Google most of the time. Note however, that we are not crawling these search engines directly. We are learning from them by means of people using Cliqz.
Then you are just copying them. What makes you think that you are independent?
Contractually, we have always been independent. Meaning that there is no contract with Google or Bing that can be cancelled and leave us without access to the results. We have never been an aggregator/meta search, as our query is resolved without a call to a third party.
Philosophically, we believe copying is a loaded term, we prefer to use the term learning. Learning from each other is something all of us do, including the big[5] corporations[6].
If you believe in our rationale for building an independent search engine, we would love to see you use beta.cliqz.com as your default search engine. If you are not satisfied with the quality yet, you could always use our products to help us to continue learning from data to get better, at some point we will be good enough for you to make the switch.