Implementing search-as-you-type in the browser using RxJS
How to combine asynchronous search streams client-side
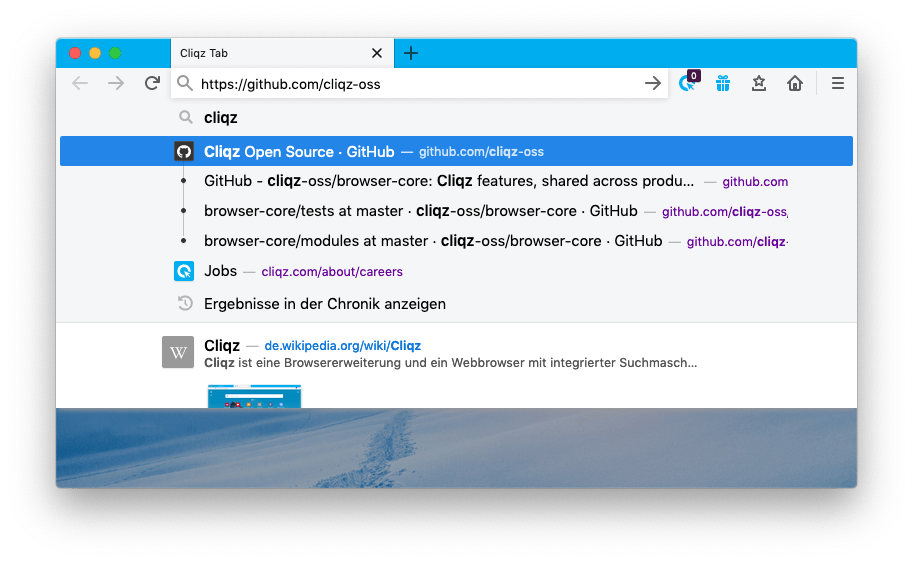
In yesterday’s post, we introduced the Cliqz Dropdown[1]—our unique approach to lightning-fast web search. A quick recap: It allows you to search the web directly from your browser’s address bar. Search results appear instantly as you type—right there inside the browser. This is also called incremental search or real-time suggestions.

This has a few advantages, first and foremost:
It is faster than loading a full-blown search engine result page (SERP), like google.com. You see the results you are looking for earlier—generally after typing only a few characters.
It is better for privacy than using one of the existing privacy-invasive search engines out there. Your queries are handled by our privacy-by-design search engine. On top, all queries are first sanitized client-side to prevent sending potentially sensitive data to our search backend from the outset.
Our search engine does not create user profiles—on purpose. Therefore, the same query from different users will return the same results[2]. Now you might object that no user profiles mean no personalization means less relevant results. But personalization and privacy are not at odds.
In fact, we do personalize search results without compromising privacy. For this, we include local browser data, like browsing history or bookmarks, and combine them with web search. This local data never leaves your browser—it is not shared with anyone. All personalization happens right inside your browser[3].
Taking this client-side approach makes the implementation slightly more challenging—or rather, more interesting—which is exactly the topic of today’s blog post.
Mixed, not stirred: combining search results client-side
Meet the component responsible for combining search results: We simply call it the mixer. Its job is to mix results from multiple sources, like our search engine backend or your local browser history.
On a traditional SERP, mixing results is a server-side job. Moving it to the client introduces a few challenges. Of course, mixing needs to be fast to deliver immediate results while typing, even on slow computers. The bigger challenge, though, lies in the asynchronous and unreliable nature of result sources. It is impossible to guarantee that results arrive in a specific order—or that they arrive at all. Let us have a look at two examples:
- A user might be offline, for example on a flight, and the search backend not reachable. Or the backend might be down. Still, the dropdown needs to reliably show results from the user’s local browsing history—it must not break or stall.
- A user’s history might be slower to respond than the search backend, for example because of high CPU load (in particular on mobile devices). Note that usually it is the other way around. Of course, we can withold backend results until history results arrive. But this introduces a (noticeable) delay. Another approach is to render history results immediately, and to append backend results later. But this leads to an unexpected result order. Both approaches impair the UX. We will describe below how we use caching to “smooth these UX edges”.
These examples suggest that naively merging result streams might not suffice. For a smooth search experience it is important to take into account UX requirements as well. For instance, users expect results to be deterministic (same query, same results) and stable (results should not jump up or down just because they were slow to arrive).
Over the last few years, we have experimented a lot to improve not only the UX of the Cliqz Dropdown, but also its search logic and performance, to name but a few. That is why our technical debt has grown—particularly in the mixer code. If nothing else, this is because coordinating multiple asynchronous input streams is complex. Eventually the sheer prospect of touching the mixer caused developers to break out in sweat. No one could be sure that this one “small fix” would not break something else in production. We eventually realized it was about time for a new solution.
Enter RxJS: re-implementing the mixer
After some research, we decided to give RxJS a shot. For those unfamiliar with it, RxJS is a JavaScript implementation of Reactive Extensions (Rx). Rx, in turn, is a library for asynchronous programming. It offers observable streams and operators known from functional programming, like map or reduce. We recommend playing around with RxJS Marbles to get a feeling for what Rx is all about. We thought that RxJS was a good match for the problems we faced—and so far, we have not regretted our decision.
For this post, we picked out a few examples to show aspects of our implementation we thought to be particularly interesting or challenging. The entire code is available as open source. But before diving in, let us have a look at the overall mixing flow for context:
- The user types a query into the address bar to search for something. Each keystroke becomes an event on the
query$[4] stream. - For each query event, the mixer starts multiple searches in parallel, one for each registered provider. A provider represents a result source, such as backend search or local history. Now, we have several
results$streams. - The mixer combines all
results$streams and applies various operators. This is were most of the work happens, like deduplication of results or caching, for example.
We suggest to keep the above flow in mind when going through the deep dives in the following.
Handling Errors. Remember the “offline example” from above? Since each provider returns its own independent results$ stream, there is little left to do for handling network issues: If there are no results arriving from one of the providers, the other providers will still work.
Discarding Outdated Results. Frequently, a user has already typed the next character of a query before providers respond with results. Such outdated results must be discarded as they do not match the current query. In RxJS, this logic is easily implemented using the built-in switchMap operator. Applied to the query$ stream this operator switches over to a new search stream whenever the query changes. As a result, previous searches are discarded. Here is a (slightly simplifed) version of our code:
const results$ = query$.pipe(
// whenever the query changes, start a new search
// (and discard previous searches)
switchMap(
// `mixResults` initiates searches on all providers
// and combines results in multiple steps
query => mixResults(query, providers)
)
);
Interrupting Ongoing Searches. Imagine that, after having finished a query, the user moves their mouse over a result to click on it. As long as the latest search request is still unfinished, this result might change any moment. In the worst case, the user is too slow to realize this change and clicks on a different result than intended.
This is a nice problem to solve with observable streams. The idea is simple: create another stream with mouse-over events, let us call it highlight$. Then stop processing results as soon as the first mouse-over event arrives. takeUntil is your friend here:
results$.pipe(
// stop taking results as soon as the first event arrives
takeUntil(highlight$)
)
Throttling Queries. Let us have closer look at the users’ queries: Throttling query$ helps to save precious resources. In particular, it is not necessary to start a new search every time a user types a character. When typing fast, the majority of results would never be used: The time between characters is too short to fetch, process, and show results. When throttling the user’s queries, it’s important to ensure that there is no delay for the first character of a search—otherwise the UI would feel sluggish. Fortunately, all this is achieved in one line using the built-in RxJS throttle operator:
query$.pipe(
// interval in ms (we use 20ms)
throttle(() => rxInterval(interval), { trailing: true, leading: true })
)
Deduplicating Results. Combining search results from multiple sources often leads to duplicate URLs. For example, the query “github” will return https://www.github.com from both the Cliqz search backend and your local browser history (assuming you are a GitHub user). The mixer is responsible for identifying and removing such duplicate URLs.
As you might have guessed, deduplication needs to run for every incoming result on either of the two result streams. For the Cliqz Dropdown, we decided that history should take precedence over backend. Therefore, in case of a duplicate URL, we remove it from backend (referred to as target$ stream) but keep it in history (referred to as reference$ stream). Again, a simplified example of our code:
// deduplication operator for two asynchronous result streams
const deduplicate = (target$, reference$) => {
// get latest results from both streams
const duplicates$ = combineAnyLatest([target$, reference$]).pipe(
// target x reference => duplicates
map(
// `getDuplicateLinksByUrl` finds duplicates given two result lists
([targetResults, referenceResults]) => getDuplicateLinksByUrl(
targetResults || [],
referenceResults || [])
)
);
// return deduplicated results stream
return duplicates$.pipe(
// combine duplicate with target result stream
withLatestFrom(target$),
map(
// deduplication is easy now, since we now what URLs
// to remove from the target results
([duplicates, targetResults]) =>
deduplicateResults(targetResults, duplicates)
)
);
};
Unlike the previous examples, deduplication is a bit more complex. It combines multiple oberservable streams, and it requires custom logic for URL handling. Still, RxJS makes the implementation rather straightforward. It simplifies handling asynchronous events, thus allowing developers to focus on the business logic.
Smoothing Results. To pick up the second example from the beginning of this post: we are looking for a way to stabilize the dropdown results. In a naive implementation, the dropdown “flickers” as results rapidly appear and disappear. This is a side effect of clearing the dropdown for each new query whenever the switchMap kicks in, as described above. Every time the user enters a new query, all current results disappear, just for new results to appear a split second later. What makes this even less acceptable is that current and new results overlap frequently. For example, “githu” and “github” produce the same first result, namely https://www.github.com.
The idea here is to cache previous results and to partially update them as soon as additional providers respond. The built-in RxJS scan operator makes this implementation quite easy. As scan accumulates events, we have access to the previous state:
results$.pipe(
scan(
(previousResult, currentResult) =>
// `smoothResults` performs partial result updates
smoothResults(previousResult, currentResult),
// initial value (result) for `scan`: no results
[]
)
)
Of course, some thought has to go into the actual smoothResults function, but at this point there is no need to know about event timing anymore.
Showing Results. Once all query$ and results$ streams are hooked up it is time to add subscribers. The first subscriber is of course the dropdown itself. For every result that has been mixed a “render results” event is broadcasted, which the UI listens to:
results$.subscribe((results) =>
action('dropdown', 'renderResults', results);
Adding new subscribers, for example one for (anonymous) product analytics, does not require touching the mixer code at all. Instead, we simply have to write a function that extracts statistical information out of results—like the number of results shown—and subscribe.
Testing. Last but not least, let us have a look at how to write unit tests for oberservable streams. We use RxSandbox, which is based on marble diagrams and makes it easy to express and understand sequences of events. For example, we have a test for the aforementioned query throttling to verify that the first character is always emitted:
it('emits first value', function () {
// the user's query: two 1s
const signal$ = sandbox.hot(' -11');
intervalMock = () => sandbox.hot('---');
// we expect the first 1 to be emitted, the second to be throttled
const expected = sandbox.e(' -1-');
// ...
});
Final Thoughts
Our RxJS-based mixer has been in production for about two years now, both on desktop and mobile. And it has been and still is continuously improving. Treating client-side search in terms of events and streams helped us to create a modular structure that is easy to reason about, easy to test, and thus easy to change with confidence.
Footnotes
Feel free to try out the Cliqz Browser for yourself on desktop or mobile. ↩︎
Assuming all users sent the same parameters when querying, such as language preferences. ↩︎
There is another layer of personalization based on short-time tasks, also done entirely client-side in the browser. If you are interested in knowing more stay tuned for follow-up articles. ↩︎
We use the
$suffix to denote RxJS observables. ↩︎