How do you spell boscodictiasaur?
Spelling correction and query completion in Cliqz search.
A cornerstone feature of modern search engines is their ability to predict and suggest what the user’s search intent is:
- without needing the user to enter the complete query (if you did not mean “facebook” when you typed “faceb”, then you are an outlier!), and,
- allowing for spelling errors in the query (we can safely assume what “soveirign state” refers to).
These predictions can be used as a shortcut for users to immediately find what they are looking for, or even enrich the current results, should the query contain spelling errors. Some users[1] even use them as an ad-hoc spellchecker.
Furthermore, query completion is critical in Cliqz search; not so much on the SERP version of it, but on the search-as-you-type (more on this in upcoming posts) on Cliqz browser. There, we offer results for every keystroke and do not know if a user has completed their query or not.
This post details how we at Cliqz tackle spelling correction and query completion: how we compute predictions, what technologies and methods are used, and how we employ our data.
The problem(s)
It is always helpful to break down problems into their constituent parts, so let us follow suit; until it is time to piece the puzzle together, we will address them independently.
We want to be able to:
- Complete a partial query (assuming no spelling errors are present).
- Correct a misspelt query into a correctly spelt one.
How it works: Completions
We don’t need to know if what we get as an input is a complete, or a partial query: we always treat it as the latter.
Assuming no spelling errors are present, completion is fairly uneventful: a straightforward approach consists in treating the input as a prefix, matching it against all queries we have seen, and return them ranked by their count[2], having the most likely completion candidates at the top.
This is what we ultimately opted for: maintain a query-count index (a few billion queries) from our query logs, stored as a trie[3] on which we can perform our lookups.
One inherent drawback, however, is the inability to complete queries related to recent event or trends, as their counts are too low. To mitigate this, we maintain a smaller (a few million), and “fresher” (all data points are less than one week old) index of query-counts that we lookup independently from our full index. Before merging full and fresh results, we artificially boost the counts of the latter.
Furthermore, we maintain another trie of N-grams () of suffixes, to handle completion of queries we have not seen before (e.g. “how to use magnanimous in a …”).
This approach covers most completion cases, however it is not unusual for these lookups to fail; all it takes is a typo[4]. Hence, the need for query corrections.
How it works: Corrections
Let us first tackle word-level corrections.
Peter Norvig has written an interesting article on the topic: the gist of it is to generate possible misspellings (edits) of words (from a vocabulary), and maintain a mapping of misspelt term correct terms, which we can query. For example, assuming our vocabulary contains the word “bed”, we have these edits:
- deletes (remove a character): bd, be, ed
- inserts (add a character): abed, baed, bead, …
- transposes (swap adjacent characters): ebd, bde.
- replacements (change a character): aed, bed,ced, …
From which we build our speller’s index:
| Misspelt Term | Correction candidates |
|---|---|
| be | bed |
| bd | bed |
| ed | bed |
| … | … |
Querying is straightforward: we lookup the misspelt term into the index, and return the corrected candidate[5].
However, generating all edits of all words from a vocabulary scales extremely poorly: to cover possible misspellings of a word of length we would have: deletions, transpositions, insertions, and replacements (using the English alphabet). The word “bed” would generate 187[6] misspellings, all of them being only one typo (or edit distance) away. Generating misspellings of an edit distance of two would yield a whopping terms.
While Norvig’s article proposes ways to tame this growth, it still remains an unfeasible approach for production systems handling vocabularies of millions of words.
A better approach is SymSpell, which uses only deletions to generate the mapping. Allow us to briefly illustrate, assuming our vocabulary contains “bed”, and “bead”:
- deletes (“bed”): bd, be, ed, d, e, b.
- deletes (“bead”): ead, bad, bed, bea, ad, be, …
Which results in the following SymSpell index:
| Misspelt Term | Correction candidates |
|---|---|
| be | [bed, bead] |
| bd | [bed, bead] |
| … | … |
| bed | [bed, bead] |
| bead | [bed, bead] |
Querying requires a bit more work this time: we have to iteratively generate delete edits for our misspelt term, look them up in our index and collect the matches as correction candidates.
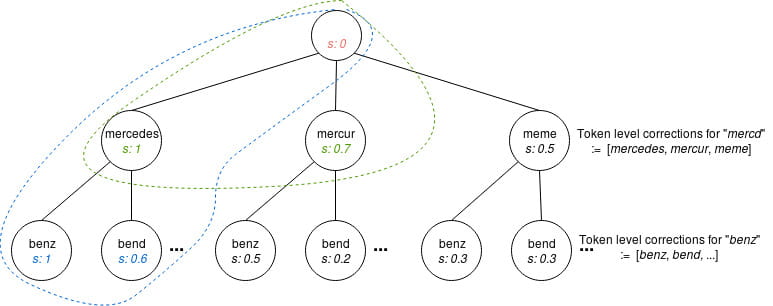
Now that we can correct words, let us attempt query-level corrections using “mercd benz” as an example of a misspelt query.
It is tempting to tokenize the query, correct each token, and join them back together into a “valid” corrected candidate. But this quickly falls flat: corrections are independent of the context they appear in, making “merkel benz”, “meme benz”, “mercur benz”, and “mercedes benz” equally valid candidates.
Regarding contextual corrections, what we opted for is a combination of iteratively generating token-level corrections using our SymSpell index, and discriminating their validity using statistical language models. Let us elaborate a bit more on the approach.
Query-level correction candidates are kept in a heap (or “beam”). For every word in the tokenized query we find its most probable token-level corrections (using our SymSpell index), and generate new query-level correction candidates. These new candidates are generated by appending our current token’s corrections to the existing query-level corrections, recomputing the score[7], and keeping only the candidates with the highest ones.
The following graphic shows how “mercd benz” can be corrected.
Piecing it together
Up to this point we have dealt with completion and correction independently, and we now have at our disposal the essential building blocks to a contextual correction and completion system.
The remainder of this section will put everything together, and delve deeper into details we have conveniently left out so far.
‘Suggest’ machine
When receiving a new query, the assumptions are that it is a partial one, and it contains no spelling errors.
Should a simple prefix-lookup on our fresh, and then full indices yield satisfactory results, the latter are ranked, filtered[8], and finally returned to the user as query suggestions.
If the initial lookups fail, we assume the query to be misspelt, and proceed to generate possible contextual corrections. Depending on the score of these corrections, we decide to either:
- Lookup our fresh and full indices again (with the corrected queries now as prefixes).
- Attempt expansion using our suffix index, keeping only expansion candidates with the highest score.
After all possible corrections and completions have been collected, a final step of ranking and filtering is carried out.
Having put everything together, we now tackle one of the two most difficult problems in Computer Science: naming things[9]. For the remainder of the post, we will refer to this system simply as Suggest.
If you are not interested in the details of the implementation, feel free to skip the following section, and continue to “A few words about the tech stack”.
‘Suggest’ machine: the gory details
We model the system’s workflow as a FSA[10], formally defined by the following objects:
State and Event
Let us clarify a bit the semantics of the states:
- init: Initialization is done. The state machine is ready to accept the query.
- expand: Expanded the query. This can refer to either Fresh, Full or Suffix expansion.
- edit: Performed query-level (contextual) correction.
- process: Performed final scoring/filtering/ranking of completions and corrections.
- final: All done, the result can be returned.
- fail: Catch-all state, if anything goes wrong during the FSA run. We can leave it out of the scope of this post.
Events can be interpreted as:
- new: New input has been provided to the machine.
- expansionmatch(type): Expanding the query (against either Fresh, Full, or Suffix ) was successful.
- editmatch(type): Contextual correction of the query was successful.
- done: The FSA run is terminated.
The argument for and denotes whether we are confident in the matches or not.
The transition function is defined as follows:
| (State, Event) pair | New State |
|---|---|
where:
(init, new) → expand(fresh): Any new query is expanded against our Fresh index at first, attempting to match recent events/trends.
(expand(_), expansionmatch(S)) → process: If we are confident about any expansion, we immediately terminate the run, perform the final processing, and return the query suggestions.
(expand(Fresh), expansionmatch(W)) → expand(Full): Having expanded the query using Fresh, but with low confidence in our expansions, we proceed by expanding using Full index.
(expand(Full), expansionmatch(W)) → edit: At this point, we have exhausted Fresh and Full expansions and collected low-confidence completion candidates, hence the next step is to try and correct these candidates into high-confidence ones.
(edit, editmatch(S)) → expand(Fresh): If contextual corrections of the low-confidence candidates yield high-confidence candidates, we retry expanding against the Fresh index.
(edit, editmatch(W)) → expand(Suffix): However, if contextual corrections yield low-confidence candidates, we try expanding the query against the Suffix index.
(expand(Suffix), expansionmatch(_)) → process: Expanding against the Suffix index is the final attempt to collect high-confidence corrections. Regardless, we proceed with processing the candidates we have collected so far.
(process, done) → final: The collected candidates are scored, filtered, ranked, and presented to the user as query suggestions.
A few words about the tech stack
The source of data for Suggest are query logs. Previous posts cover them in detail, so I will not digress dwelling on them for too long: for our intents and purposes, they contain queries and respective counts, which we extract and use to build our Full, Fresh, and Suffix trie-s (to handle completions); language models, and misspelt word-possible corrections index (to handle corrections); and other auxiliary datasets.
As our datasets are built from eachother, a change in any dataset that is used to derive other ones implies re-computation for all the dependent datasets. We model this dependency graph using Spotify’s Luigi.
Before employing these datasets, however, we compress them using Keyvi, a key-value index developed in-house, optimized for lookup performance and size, also having built-in utilities for completions (e.g. prefix, and fuzzy lookup) which we use extensively in Suggest.
Language models are handled with KenLM, since it provides tools to be able to customize the models’ parameters, and offers utilities regarding model compaction and querying.
From a system point-of-view, with Suggest being one of the first entrypoints to our backend and having to compute suggestions for every keystroke of our users, it is of paramount importance to be able to concurrently handle a massive amount of parallel requests, and respond to them as quickly as possible: Rust was our weapon of choice, due to its inherent concurrency safety, speed, and rich ecosystem of libraries.
Conclusions (and this boscodictiasaur thing)
By using the technologies and methods presented in the previous sections, we are able to:
- generate and update our datasets on the fly,
- store them efficiently, and to
- handle multiple concurrent requests, with a low response time.
With Suggest being in an alpha state, and as is the case with production systems, there is always room for improvement.
To name a few ongoing developments:
- Smarter ways to build our indices: the system’s response time scales with its index sizes. We are therefore exploring ways of reducing their memory footprint without compromising quality.
- Ranking and scoring enhancements: the results can be unexpected for some cases (try it out!), which can be handled by tweaking the scoring heuristics and adopting language models trained on different parameters.
Finally, to answer the question you didn’t know you had: it is spelt with a silent M, apparently.
Remarks and references
Definitely not the author of this post. ↩︎
How many times we have seen that exact query in our query logs. ↩︎
Not quite. These data structures are handled by Keyvi: you can read more about them here ↩︎
Admittedly, a bit of an exaggeration, as the implementation is a bit more resilient than that. ↩︎
We have purposefully omitted the ranking of these candidates, as we are mostly concerned with getting correct candidates at this point. ↩︎
182, to be precise. 187 is an upper bound produced by the formula. ↩︎
The score assigned to the correction candidates is a function of their edit-distance from the input query, their length, and language model score. ↩︎
Some suggestions are not suitable to be presented to the user (e.g. explicit content), despite being contextually valid. ↩︎
The others being: cache-invalidation, and off-by-one errors. ↩︎