Cliqz Rich Results
What are rich results, how can they enhance the search experience and how are they served?
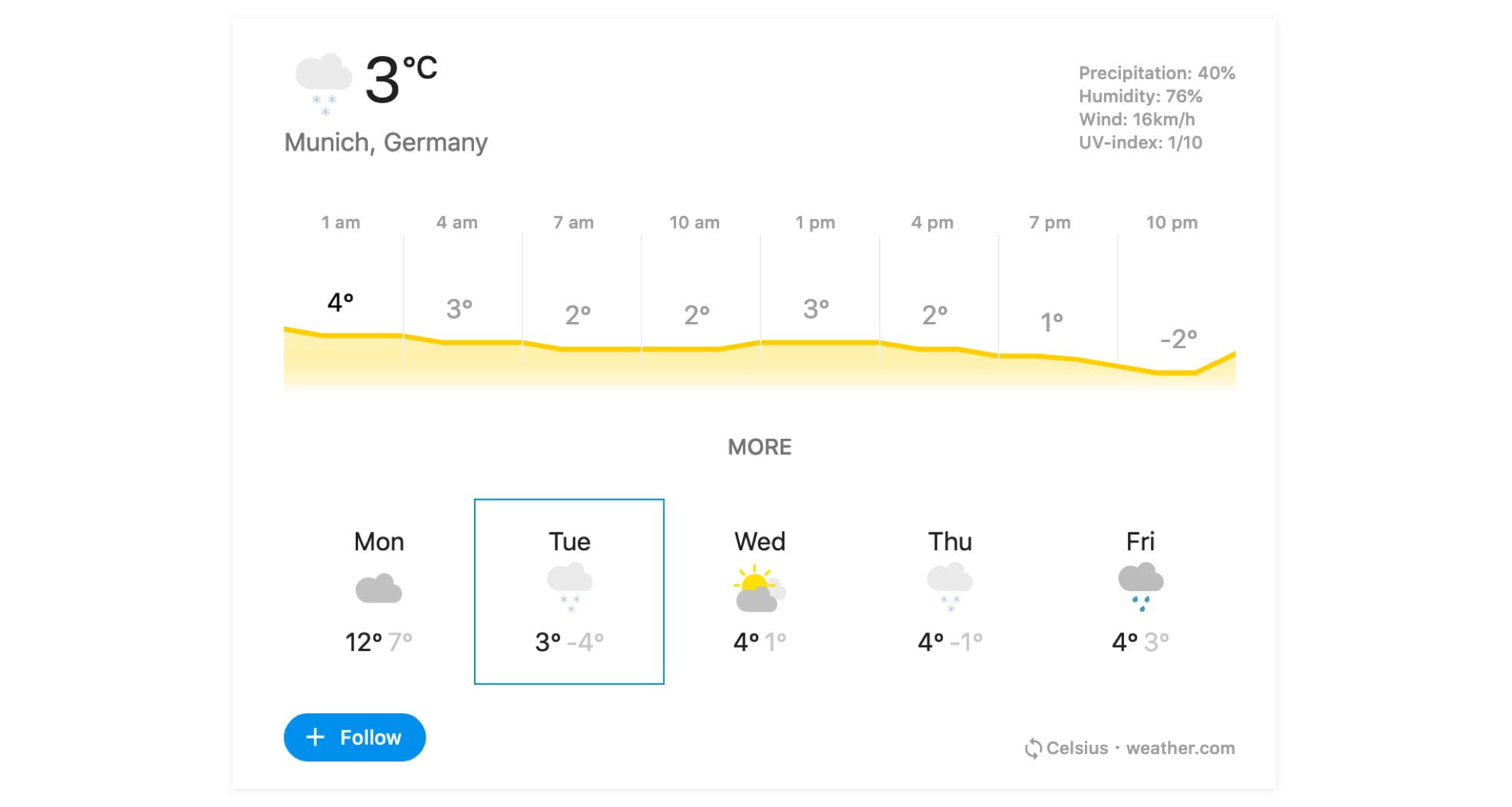
A recent study found that a majority of all browser-based searches on Google are now “zero-clicks”, which means that the user did not need to visit any url found in the result list. Instead, the information is consumed directly from the Search Engine Results Page (SERP). There are many reasons why this happens, but a fundamental truth is that users’ expectations of the nature of results has evolved. There are certain types of queries for which users expect an answer as opposed to a destination where an answer can be found.
This is a trend that we also observe at Cliqz and we have been working for years on polishing those special results, both in our “search-as-you-type” product in the Cliqz browser and more recently on beta.cliqz.com. We call them: Cliqz Rich Results.
A Quick Tour of Rich Results
A rich result is special in that it embeds the information requested by a user into the search result page itself. The goal is to allow users to save time, but also to enhance the search experience by introducing new interactive kinds of results and, overall, make search more useful and visually appealing. At Cliqz, those special results are served by a system called Rich Header.
We distinguish three kinds of rich results:
- Navigational results consist in a selection of quick links which allow faster navigation to internal pages of a website.
- Enriched results embed part of a page’s content or additional information from third-party databases or services.
- Non-clickable results do not lead to any web page; instead, they display useful and directly consumable information to answer a specific query.
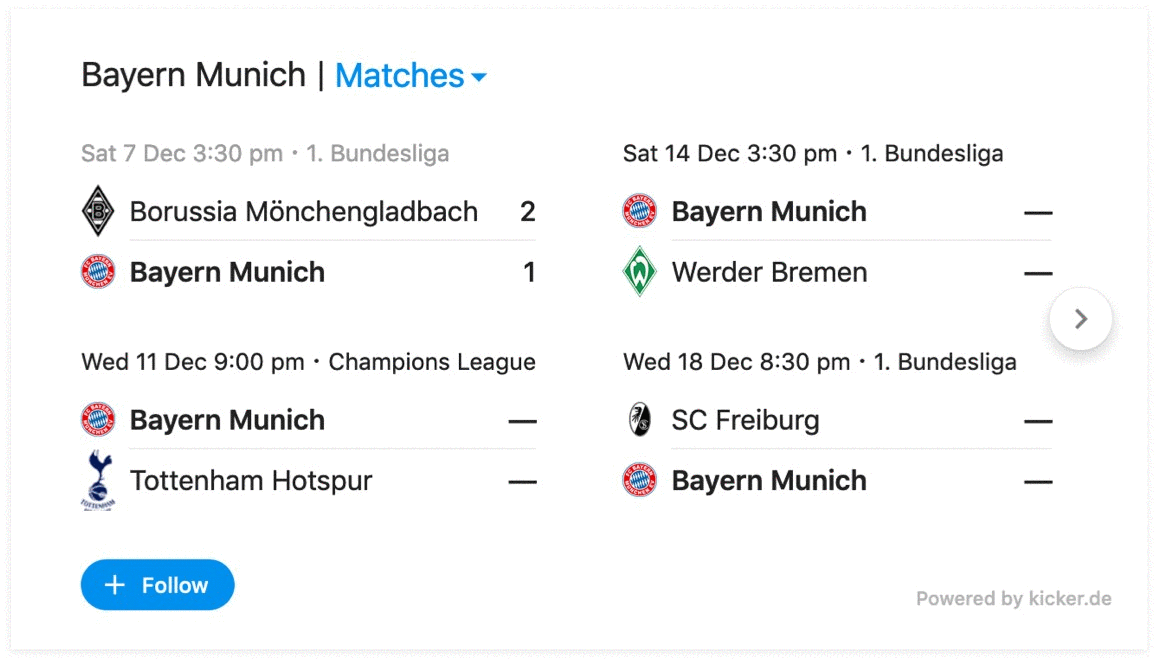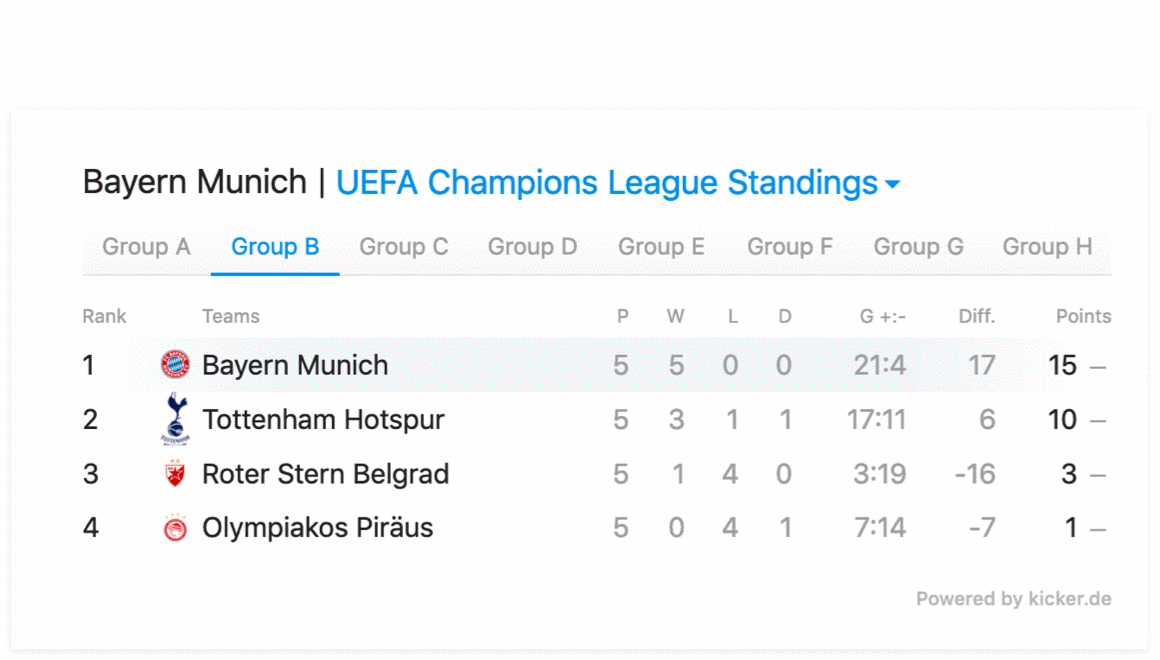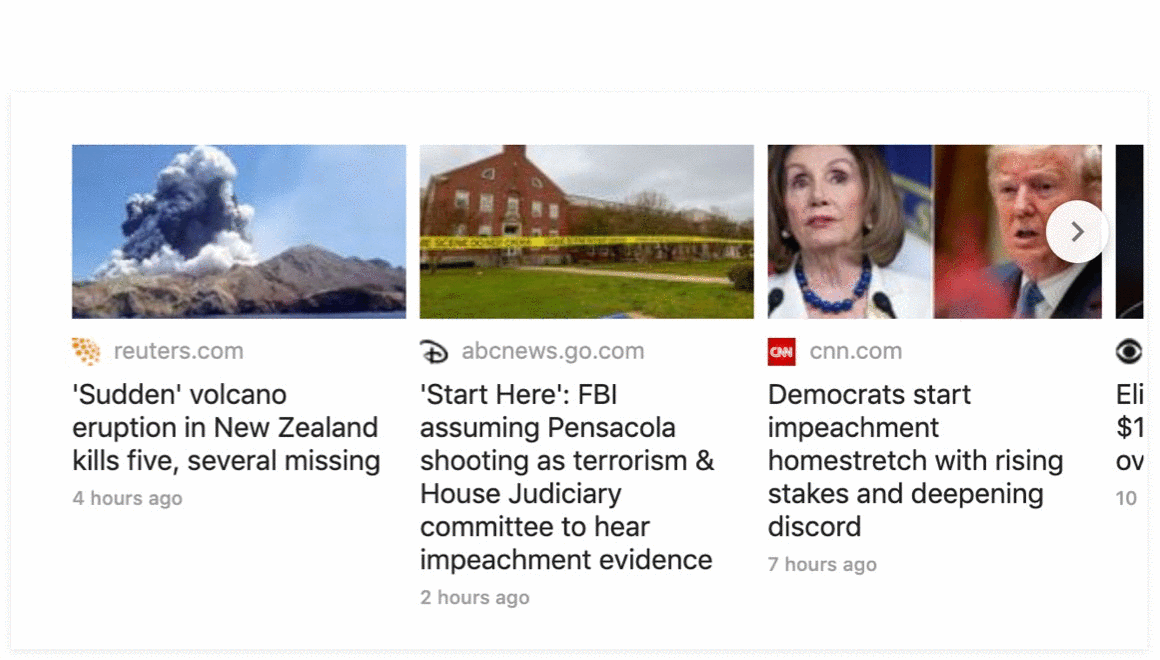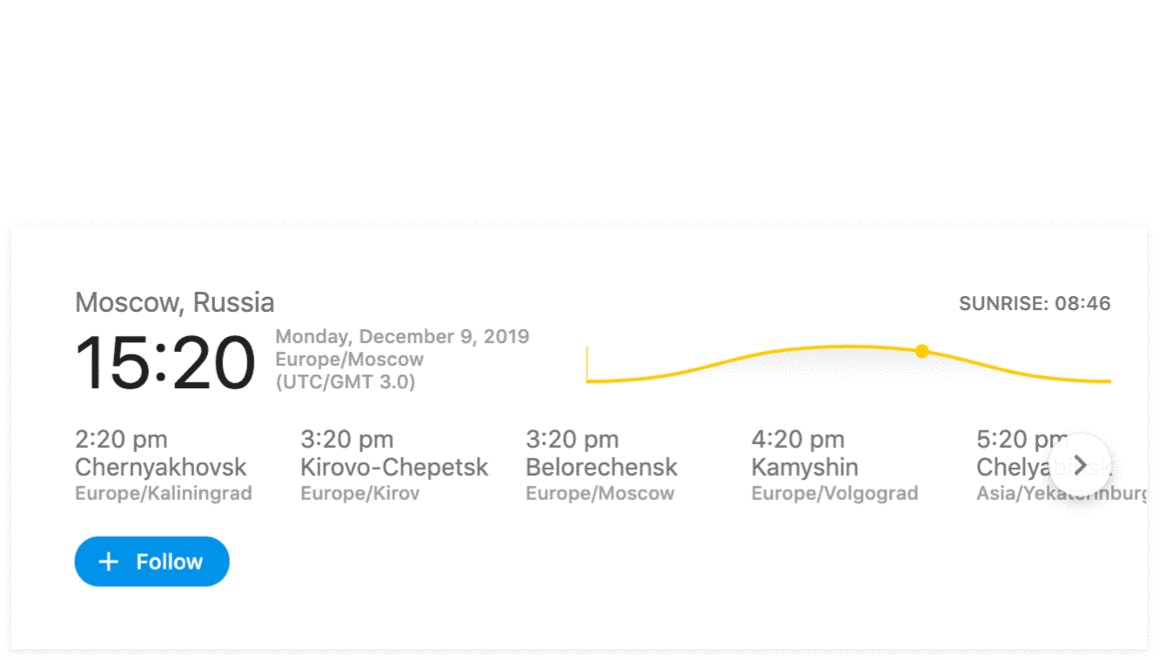
To Show or Not to Show?
The single most important question we need to answer before deciding if rich results should be shown for a given query is: What is the user’s intent? Does a user want to know the weather forecast in Hamburg or travel there? Is the user interested in seeing the lotto’s winning numbers?
Because rich results will usually be shown in the first position and take a significant amount of space on the SERP, we need to minimize false positives. The service that is in charge of detecting intents and deciding which results to trigger is called Rich Mapper. It has four main ways to detect a user’s intent.
1. Exact Query Match
Exact matches allow us to specify a static mapping of queries to rich results to trigger. This method is fast and precise. Furthermore, using a caching layer allows us to handle a very large number of queries. However, the coverage is low, since only a fixed set of intents can be detected that way. Here are a few examples:
| Query | Corresponding Rich Result |
|---|---|
| time russia | Time |
| bundesliga table | Soccer Standings |
| premier league | Soccer League Games |
| fc bayern | Soccer Team Games |
| cliqz | Generic With Quick Links |
2. Query Pattern Match
To overcome the low coverage of exact query matching, we also rely on fuzzier query patterns implemented using regular expressions. Compared with exact matches, each pattern is able to capture multiple variations of the same intent. Let us take the example of the flight status rich result; we need to be able to trigger based on different flight companies and numbers, which cannot be implemented with exact matches (we cannot enumerate all of them): LH 001, LH 002, …, AF 001, … On the other hand we can describe how a valid flight query looks like. This is a simplified version of our flight status pattern: (LH|AF)\s+[0-9]{1,3}[1]. Here are examples of queries handled with patterns:
| Query | Corresponding Rich Result |
|---|---|
| LH 112 | Flight Status |
| 13 eur in usd | Currency Conversion |
3. Exact Result URL Match
In the case of exact result match, we rely on the search backend to detect the intent behind each query. Rich Header then analyzes the set of resulting URLs and checks if domains correspond to a static mapping to rich results.
| URL | Corresponding Rich Result |
|---|---|
cinemaxx.de (coming soon) | Cinema Showtimes |
| amazon.com | Generic Quick-Links |
| spiegel.de | Navigational News |
| yt rihanna diamonds | Video |
4. Partial Result URL Match
Whenever a URL path starts with a specific sub-path (e.g. timeanddate.com/weather pattern would match https://www.timeanddate.com/weather/germany/munich/ext), a rich result can also be triggered. This matching can be efficiently implemented using a trie data-structure. This method is both fast and memory efficient. Although this is an internal mechanism the results can be triggered using the following queries:
| URL | Corresponding Rich Result |
|---|---|
| timeanddate.com/weather/germany | Weather Forecasts |
| fcbayern.com/en | Soccer Games |
| time.is/Munich | City Current Time |
Where does the data come from?
Each rich result leverages data from a different source. Some of the data is provided by third-party services—you can see the attribution at the bottom of each snippet on our SERP—, while other sources are curated internally at Cliqz.
This diversity of sources and data formats increases complexity, especially when operating under low time budgets; each request having to be fulfilled in a handful of milliseconds, while not being able to control the latency of third-party APIs.
There are a few ways which we use to tackle this problem. First of all, we rely heavily on server-side caching to make sure that similar requests from different users will be served with very low latency and do not incur extra work on our side. Additionally, we follow two strategies:
- Whenever the number of possible requests is small enough and the third-party API allows it, we fetch results ahead-of-time to populate our cache. This is the best scenario for us as it allows to serve all requests with low latency with no externalities. Unfortunately, this is not always possible, especially when the data of rich results is time or location-dependent (e.g. weather forecast).
- As a fallback, we use a long polling scheme where the first user to request a specific snippet triggers an asynchronous request to fetch the data. Whenever the request is fulfilled, the cache will be populated and the entry can be re-used for sub-sequent similar requests. In the meanwhile a promise is returned to the user and the snippet will be displayed when ready. The effectiveness of this approach depends heavily on the frequency of cache misses but yields good results in practice.
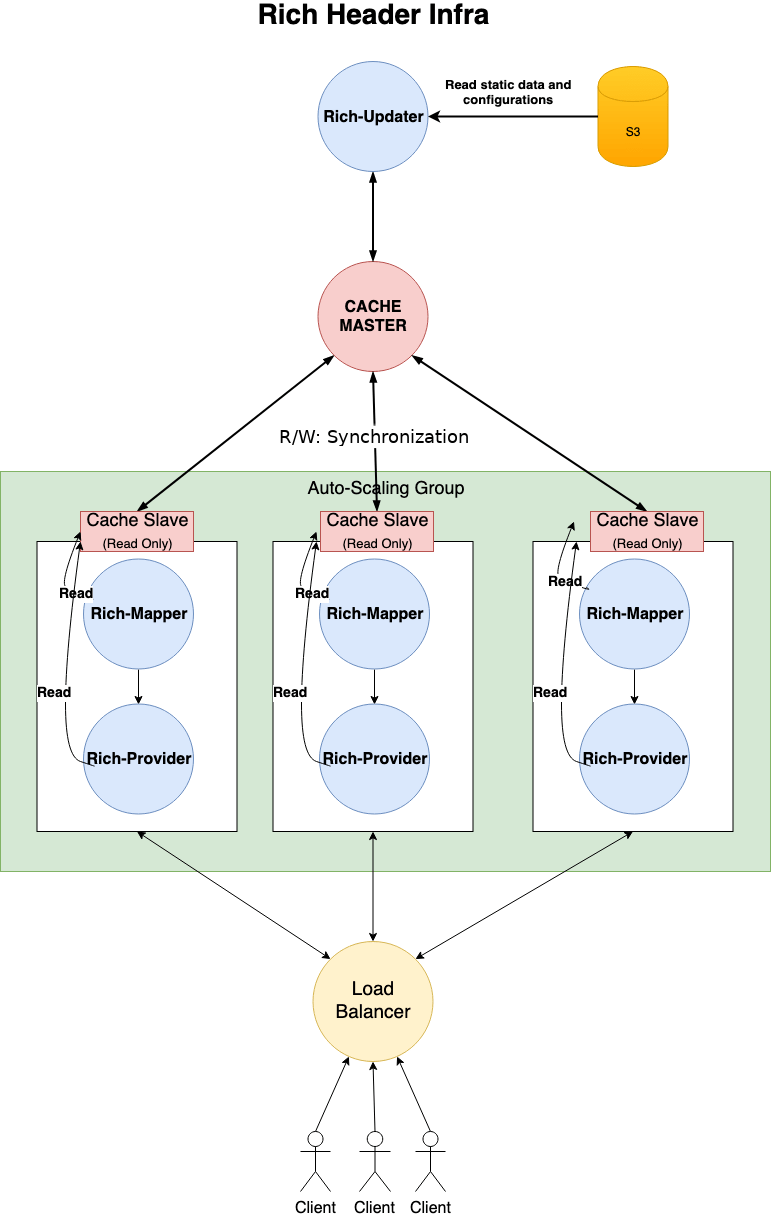
To understand better how all these pieces fit together, let us now give an overview of the Rich Header infrastructure.
The Infrastructure Behind Rich Header
An important requirement for Rich Header is to respond reliably and with a low latency, even under high loads. To do so, the infrastructure is split into several components which can be scaled as needed:
- The Cache is the storage layer used by all components to persist information and retrieve it with very low latency. To allow handling high loads, the cache’s topology is: one master and several slaves. Slaves are read-only, so that the response generation can be very fast. The uniqueness of the master makes the synchronization efficient and consistent.
- The Mapper is in charge of deciding which kind of rich result should trigger based on a user’s query. This is the system described above. Once an intent has been detected, the query is forwarded to the appropriate provider.
- Providers generate the final response for each rich result. Each provider is bound to a cache instance where read-only operations are made. Write operations and updates are started in the background from providers. They are handled by the updater.
- The Updater handles background updates when needed. Often, generating the data needed by providers takes time; for instance when fetching data from multiple external providers is required. Whenever it is possible, those operations are made through the Rich Updater. The generated data are cached and ready for the Rich-Providers.
Performance
Performance is critical for Rich Header. Our core search products, beta.cliqz.com and the browser dropdown, depend on results to be served as fast as possible. In the case of the dropdown, each key pressed by a user potentially triggers a query to the search backend. Each query needs to be processed by Rich Header and only a fraction of them lead to rich results, still, we serve hundreds of thousands of these every day.
Waiting a long time for the results to be available would quickly degrade the user experience. Although we care a lot about making the implementation of each component as efficient and lean as possible, it does not always suffice, especially when the number of queries grows and exceeds the capacity of a single server. To go further, scaling the infrastructure is required.
Horizontal Scaling
Each query is handled by a group of one mapper, one provider and one cache instance. Horizontal scaling is achieved through the instantiation of more of these units, which allows to serve more requests in parallel. Modulo some complications at the storage layer, the number of requests which can be served increases nicely with the number of units that are running in parallel.
Vertical Scaling
Vertical scaling is about the number of different rich result providers implemented. From a request processing perspective, increasing the number of different result providers increases the pressure on the read-only cache instances, which can be solved by instantiating more of them as mentioned previously.
Another issue arises at the updater level. Each provider can start background jobs to fetch and process data needed to answer queries. Increasing the number of supported rich results might lead to a higher load on the updater which is in charge of scheduling these tasks. This also leads to an increased pressure on the master cache instances and data synchronization can become an issue. Luckily, the number of different rich results increases slowly enough that we can keep track of it easily.
Future
Rich Header is a system that our users care about deeply, for it is both useful and eye candy. The main challenge ahead is to increase coverage while maintaining a slim, scalable system. The way we decide on what kind of results are to be enriched next, depends primarily on the volume of queries that would trigger such results. By using Cliqz Search you are helping us define what the next ones are.
Footnotes
If you are not familiar with regular expressions, the pattern
(LH|AF)\s+[0-9]{1,3}will trigger for every query starting with eitherLHorAF, followed by one or more spaces and ending with a number of length up to three digits. ↩︎